
Штучний інтелект увірвався у всі сфери нашого життя: від автовідповідача в банку до архітектури.
Midjourney, Stable Diffusion, Dall-e, Lensa – це далеко не повний список тих додатків, які за останні декілька років сколихнули суспільство інноваціями у створенні нового контенту за допомогою штучного інтелекту. Проте зараз штучний інтелект став не лише творцем неймовірно правдоподібних картин, фото чи відео, а й причиною судових позовів щодо порушення авторських прав. А чому так відбувається та чим таке особливе авторське право, коли йдеться про штучний інтелект, – розберемось в аналітиці Центру демократії та верховенства права.
Що таке штучний інтелект та чи може він порушувати авторські права митців?
Сучасний “штучний інтелект” (далі – ШІ) – це сукупність наук і методів, яка здатна обробляти дані для вирішення дуже складних комп’ютерних задач. Раніше ми детальніше описали роботу ШІ у статті “Штучний інтелект у правосудді”. Так, ШІ наділений людськими якостями й окрім вирішення проблем, він здатний навчатися. Тому важливою його частиною є машинне навчання (Machine Learning, або ML).
Сучасний ШІ працює за принципом “змішування” декількох прикладів того, на чому він навчається. В результаті виходить новий об’єкт, який запозичує стиль у інших. Наприклад, зображення, згенероване за рахунок такого “змішування” матиме достатньо відмінностей від оригінальних зображень, щоб вважатися новим об’єктом.
На фото нижче зображений процес дифузії, де перший етап полягає в тому, що до зображення (або інших даних) за кілька кроків додається візуальний шум. Цей процес наведений у верхньому рядку діаграми. На кожному кроці ШІ фіксує, як додавання шуму змінює зображення. На останньому кроці зображення “розсіюється” у практично випадковому шумі.
Другий етап схожий на перший, але у зворотному порядку. Цей процес зображений у нижньому рядку діаграми, який слід читати справа наліво. Зафіксувавши кроки, які перетворюють певне зображення на шум, ШІ може виконати їх у зворотному порядку і згенерувати копію оригінального зображення. Так штучний інтелект визначає, який спосіб та особливості застосувати у конкретному випадку.
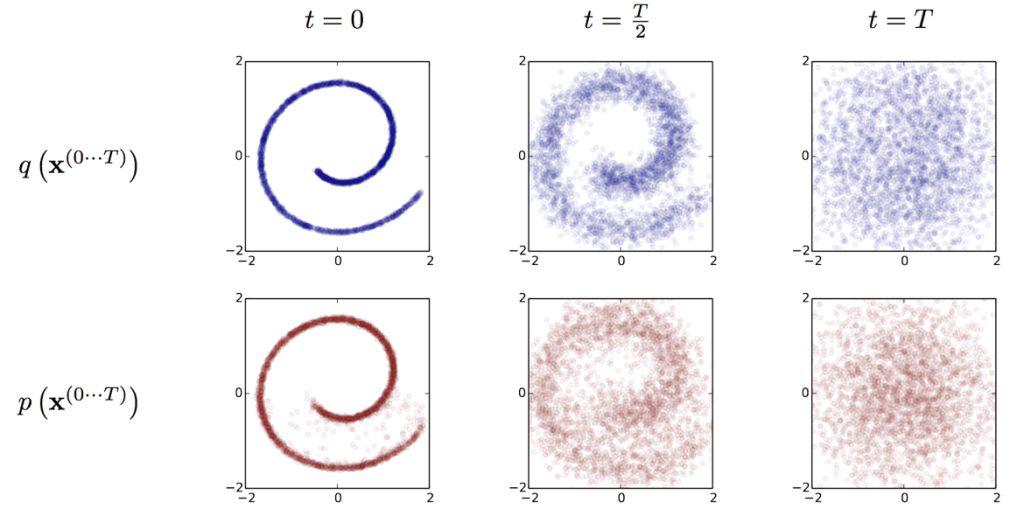
Джерело: Stable Diffusion litigation
Сучасні програми штучного інтелекту (наприклад Midjourney, Stable Diffusion, Dall-e, Lensa) для того, щоб згенерувати картину, навчаються на базі картин чи зображень, які знаходять в Інтернеті та усіх відкритих базах. А ці об’єкти мають авторів, чиї права захищені. Після цього програма використовує аналогічний спосіб чи концепцію авторів оригіналу твору, аби згенерувати нове фото, відео чи картину.
Якщо ШІ має “писати” вірші, його навчають за допомогою поезії, яку показують ШІ у великих обсягах. Тоді він використає аналогічний принцип, аби створювати текст. Якщо необхідно, щоб ШІ генерував картини, йому показують безліч картин.
Важлива ознака цього процесу: штучний інтелект не копіює результат творчості автора, а лише користується концепцією чи способом творення автора оригіналу твору.
Тут важливо звернути увагу, що ідеї, методи, концепції, принципи, способи, відкриття не охороняються авторським правом. Результати роботи ШІ статистично нагадують те, на чому він навчався, але не копіюють оригінали.
Адже штучний інтелект змішує картини, фото чи відео між собою, щоб створити новий об’єкт. Тому – жодного порушення авторського права немає, оскільки програми використовують твори мистецтва, захищені авторським правом, суто для навчання та змішування між собою.
Результат такої роботи ШІ не можна вважати і похідним твором, адже похідний твір – це твір, що є результатом творчої переробки іншого твору без завдання шкоди його охороні (анотація, адаптація, аранжування, кавер-версія, обробка нематеріальної культурної спадщини тощо) чи його творчим перекладом іншою мовою. Ключове в цьому контексті те, що діяльність ШІ не є творчою діяльністю, тому створити похідний твір він не може.
А звідки ж ШІ бере матеріали для тренувань? Досить часто він використовує твори, які є у відкритому доступі, належать до суспільного надбання або просто опубліковані в Інтернеті. Авторське право дозволяє збирати дані для тренувань в Інтернеті – це вважається добросовісним використанням. Втім, у мережі є багато так званих “піратських матеріалів”, а вже їх використання порушуватиме авторські права.
Як законодавство України регулює результат роботи штучного інтелекту
1 січня 2023 року набрав чинності новий Закон України “Про авторське право і суміжні права”. Детальний розбір цього закону ви знайдете у статті ЦЕДЕМ “Новий Закон “Про авторське право та суміжні права”. Які зміни відбулись у переліку об’єктів авторського права?”.
У цьому законі результат роботи штучного інтелекту підпадає під правове регулювання як неоригінальний об’єкт, згенерований комп’ютерною програмою, що охороняється правом особливого роду (sui generis).
Sui generis – це набір спеціальних положень, які відрізняються від загальних. Вони регулюють об’єкти, створені внаслідок роботи комп’ютерної програми. Ці об’єкти не містять творчого підходу та генеруються без участі людини. Як результат, особисті немайнові права на такі об’єкти не виникають, адже вони можуть належати лише фізичній особі, але аж ніяк не штучному інтелекту.
Такі права особливого роду починають діяти з моменту, коли комп’ютерна програма згенерувала результат, а їхній строк чинності спливає через 25 років з цього моменту.
Якщо штучний інтелект згенерував результат, використавши інший об’єкт авторського права, тоді користуватись таким результатом ШІ можна лише у випадку, якщо не порушені авторські права щодо цього об’єкту. Наприклад, якщо штучний інтелект створив кліп, використавши уривки захищеного авторським правом відео – потрібно дотримуватися авторських прав щодо використаного контенту.
Чи може ШІ законно отримати доступ до даних, на яких тренуватиметься для генерування нового контенту?
В європейському законодавстві чинною є Директива Європейського парламенту та ради про авторське право та суміжні права на Єдиному цифровому ринку, стаття 4 якої містить положення про можливість “відтворення та вилучення правомірно доступних творів та інших об’єктів з метою інтелектуального аналізу текстів і даних”. Це означає, що спосіб навчання на великій кількості інформації, який використовує штучний інтелект – цілком законний та не порушує авторських прав на території ЄС.
На території США чинною є доктрина добросовісного використання. Вона регулює питання законності використання творів, що захищені авторським правом. Відповідно до її положень, створення електронних бібліотек чи, наприклад, копій для підготовки ескізів зображень вважається добросовісним використанням. Основна ідея така: копія виконує іншу функцію, ніж оригінальний твір, і не створює його заміну. Тому навчання штучного інтелекту в такий спосіб – цілком законне.
По суті, вивчення захищеного авторським правом контенту з різних інтернет-джерел для навчання штучного інтелекту не є прямим порушенням. Проте, варто пам’ятати, що в різних юрисдикціях діють різні закони про авторське право – а тому варто уважно перевіряти, під яку юрисдикцію потрапляє той об’єкт авторського права, який ви плануєте використати для навчання штучного інтелекту.
Чи може штучний інтелект бути автором творів?
Штучний інтелект не може мати авторського права на згенеровані фото, відео чи картину. Це пов’язано з тим, що концепт авторських прав від самого початку стосувався лише людей і їхньої творчості.
Проте є винятки, коли авторське право на результат роботи штучного інтелекту виникає. Це можливо, якщо до процесу створення зображення, відео чи картини була залучена людина. Для цього вона має не лише визначити певні параметри для програми штучного інтелекту та підібрати певний твір, на базі якого штучний інтелект згенерує твір, а й внести свої корективи. Це передбачено у статті 33 Закону України “Про авторське право та суміжні права”, в якій зазначається, що твори, створені фізичними особами з використанням комп’ютерних технологій, не вважаються неоригінальними об’єктами, згенерованими комп’ютерною програмою.
Наприклад, якщо людина визначить певні параметри роботи ШІ, а потім внесе свої корективи у результат роботи, то вона може претендувати на авторство.
Однак і в такому разі слід зважати: чи був результат роботи людини, котра вносила правки, творчою діяльністю? Наприклад, людина може вставити дві крапки у згенерований ШІ текст. В одному тексті вони абсолютно не змінять рівень оригінальності твору, а в іншому – навпаки. Якщо навіть дрібна зміна вплине на рівень оригінальності твору – її творець може претендувати на авторство.
Чітких загальних критеріїв, аби визначити оригінальність твору, наразі не існує. Проте, як свідчить практика, аби твір вважався оригінальним, у ньому має бути певний рівень новизни та результату інтелектуальної діяльності автора. Зараз рішення щодо оригінальності творів породжують безліч дискусій навіть у судах.
Судова практика у справах, пов’язаних зі штучним інтелектом
Європейський суд з прав людини розглянув справу “Centrum för rättvisa проти Швеції” (заява № 35252/08), що стосується автоматизованого радіоелектронного перехоплення сигналів.
Заявник стверджував, що під час своєї роботи щоденно спілкується з особами, організаціями та компаніями у Швеції та за кордоном за допомогою електронної пошти, телефону та факсу. Проте він побоюється, що його розмови перехопить радіоелектронна розвідка. Таке підслуховування є автоматизованим і повинно стосуватися лише певних сигналів.
ЄСПЛ заявив, що вплив автоматизованої радіоелектронної розвідки на захист приватності дійсно є негативним. Проте суд вважає, що такі системи важливі для національної безпеки.
Як результат, судді ухвалили рішення: система не має значних недоліків у своїй структурі та розвинулася достатньо, щоб мінімізувати ризик втручання у приватність та компенсувати відсутність відкритості.
Нещодавно компанії Microsoft, GitHub та OpenAI зазнали критики через використання свого інструменту Copilot на основі штучного інтелекту.
Copilot – це програма, що працює на базі технології OpenAI та прямо у редакторі створює рядки коду для айтівців. Програма навчається завдяки загальнодоступному коду з GitHub. Юристи почали заявляти, що такий інструмент порушує закони про авторське право, оскільки базується на “піратстві програмного забезпечення у безпрецедентних масштабах”. З цієї причини, юрист Метью Баттерік з іншими правниками звернулися з груповим позовом проти компаній до федерального суду Сан-Франциско.
Проте, Microsoft, GitHub та OpenAI подали заяву, в якій стверджують, що “Copilot нічого не вилучає з відкритого вихідного коду, доступного для громадськості. Натомість Copilot допомагає розробникам писати код, генеруючи пропозиції на основі того, чого він навчився з публічного коду”.
У Каліфорнії в січні 2023 року зареєстровано позов до платформ Midjourney, DeviantArt та Stability AI, який подали художниці Сара Андерсен, Келлі МакКернан і Карла Ортіс. Причина позову – штучні інтелекти використовували картини художниць без їхньої згоди. Авторки вимагали компенсації за завдані збитки через порушення авторських прав, правил DeviantArt, закону DMCA та законів про захист від недобросовісної конкуренції.

Ліворуч – зображення, що згенерував ШІ. Праворуч – комікс Сари Андерсон (Джерело: NY Times)
Окрім цього, художниці хотіли отримати підтвердження того, що вони зможуть запобігти подібній ситуації в майбутньому. Ймовірно, для цього необхідно, щоб штучний інтелект видалив будь-які дані, які стосуються авторського твору. Зараз справа – на ранньому етапі розгляду. Про сучасний стан справ щодо цього позову ви можете прочитати тут.
Чи може штучний інтелект забути вивчене?
Наразі розробники ШI запевняють, що вилучити контент з уже натренованого ШІ неможливо. Вони пояснюють це тим, що ШІ не здатен забувати те, на базі чого навчався генерувати новий контент.
У такому разі варто з’ясувати, чи діятиме щодо ШІ право особи на забуття. За ним, людина може звернутись до пошукової системи із запитом: видалити результати пошуку з її ім’ям. Такою пошуковою системою може бути, наприклад, Google. Враховуючи специфіку роботи ШІ, до нього також можна застосовувати право особи на забуття. Адже він бере всю інформацію з пошукових систем.
В будь-якому разі, автори, які цим переймаються і хочуть належно захистити свої роботи від штучного інтелекту, можуть самостійно подбати про це. Як саме – описуємо нижче.
Як захистити свій твір від штучного інтелекту?
Відповідь – іншим штучним інтелектом. Три згадані вище художниці створили спеціальну програму під назвою NO AI. У цьому застосунку автори можуть захистити свою картину чи зображення від потрапляння у бази нейромереж.

(Джерело: NO AI)
Для цього в NO AI необхідно поставити водяний знак, який і буде захищати роботу від використання штучним інтелектом. Справа в тому, що ШІ під час пошуку нових зображень для навчання використовує лише твори, чий автор – людина. Зображення, на яких така вотермарка поставлена, штучний інтелект вважає результатом роботи іншого ШІ, а тому не пропускає їх до своїх баз. Адже творіння штучних інтелектів для машинного навчання не підходять.
ChatGPT та авторське право
Як ми вже зазначали вище, авторське право має лише людина, тому відповіді ChatGPT не захищені законом про авторське право. Тобто результат, згенерований ChatGPT, по суті можна використовувати без ліцензії чи дозволу.
Проте, оскільки для генерування відповідей чат використовує всю наявну в Інтернеті інформацію, ви можете зіштовхнутися з ризиками.
Наприклад, чат може відповісти вам текстом, який захищений авторським правом, і якщо ви просто скопіюєте його та використаєте – порушите авторське право іншої людини. Саме тому не варто сприймати чат як творця текстів і слід уважно перевіряти отриманий результат на наявність плагіату.
Серед інформації чи творів, які може потенційно використати ChatGPT, можуть бути і торговельні марки або патенти (наприклад, чат згенерує відповідь, яка містить логотип). Ці об’єкти теж захищені авторським правом, і їхнє використання без дозволу матиме юридичні наслідки.
Тому, наприклад, якщо у згенерованій відповіді ChatGPT будуть цитати з праці, захищеної авторським правом, особі, що використала їх, доведеться віднайти оригінал твору, щоб зазначити автора цитати і не порушувати авторське право іншої особи. На жаль, досить складно неозброєним оком побачити у відповідях чату GPT матеріали інших авторів. Втім, завжди можна перевірити згенерований у ChatGPT текст на плагіат. Наприклад, у Quetext.
Інша проблема – як визначати, хто написав текст: чат чи людина? З нею останнім часом зіштовхнулось безліч викладачів в університетах, оскільки студенти значно частіше користуються чатом, аби писати свої роботи, і виявити це з першого погляду – практично неможливо. Проте згодом OpenAI випустила додаток, який допомагає розпізнати, чи був текст згенерований штучним інтелектом. Тож ця проблема вже вирішена.
Чому забороняють використовувати результати роботи ШІ
Наразі деякі платформи починають забороняти продавати та завантажувати ілюстрації, що були створені штучним інтелектом. Про це заявив Крейг Пітерс, генеральний директор Getty Images, у коментарі виданню The Verge.
Знову ж таки, пов’язано це з захистом авторського права та питаннями до законності використання таких зображень. Інші платформи також починають обмежувати використання зображень, згенерованих ШІ. Так, Shutterstock та платформа FurAffinity заборонили використання згенерованих ШІ зображень.
У свою чергу, організатори Міжнародної конференції з машинного навчання (ICML) заборонили авторам користуватися ChatGPT для написання наукових робіт. На конференції заявили, що “статті, які містять текст, згенерований за допомогою великомасштабної мовної моделі (LLM), такої як ChatGPT, заборонені, якщо тільки створений текст не є частиною експериментального аналізу статті”.
Як результат, в соціальних мережах спалахнула дискусія між дослідниками ШІ та науковцями, під час якої звучали як критика так і захист ШІ. Тому організатори опублікували заяву, в якій пояснили, що поява загальнодоступних мовних моделей штучного інтелекту, таких як ChatGPT, є “захопливим” розвитком, який, тим не менш, має “непередбачувані наслідки і питання без відповідей”. До таких питань у ICML віднесли те, що внаслідок такої роботи ШІ складно встановити, хто є власником результату роботи, адже штучний інтелект навчається на публічних даних. А серед них досить часто трапляються тексти, які дослівно копіюють частини тексту праць, захищених авторським правом.
Тут важливо те, що ICML забороняє лише текст, який був “повністю створений” штучним інтелектом. Саме тому організатори заявили, що не забороняли використання ChatGPT “для редагування або змін написаного автором тексту”. І додали, що багато авторів уже використовують для цього “напівавтоматизовані інструменти редагування”, наприклад Grammarly, та різні форми онлайн-словників і систем машинного перекладу. Проте ICML заявляє, що заборону на текст, згенерований штучним інтелектом, переглянуть наступного року.
Минулого року Stack Overflow заборонив користувачам надсилати відповіді, створені за допомогою ChatGPT, а Департамент освіти Нью-Йорку заблокував доступ до чату для всіх користувачів своєї мережі.
Рекомендації
Штучний інтелект розвивається надзвичайно стрімко, саме тому в сучасному світі виникають ситуації, з врегулюванням яких люди зіштовхуються вперше. Наразі у штучного інтелекту та способів роботи, які він використовує для генерування творів, є свого роду повна вседозволеність. Зараз ризики розвитку ШІ у тому, що способи його роботи поки такі інноваційні та швидкі, що законодавці не завжди встигають регулювати його дію у всіх сферах життя.
Окрім цього, поширення ШІ збільшує ризики дезінформації (вона може з’являтися у текстах, згенерованих ШІ), як і кількість випадків порушення авторського права. Які виклики кине людству штучний інтелект у майбутньому – можна лише здогадуватись. Проте у вас є надійні способи дотримуватися авторських прав інших людей:
- Творці, які бажають захистити свої об’єкти інтелектуальної власності, можуть користуватись програмою NO AI.
- Аби перевірити, чи у згенерованому штучним інтелектом тексті немає плагіату, використовуйте додатки для перевірки тексту, зокрема Quetext.
- Для того, щоб перевірити зображення, згенероване ШІ, на плагіат, використовуйте Google Reverse Image Search, призначений для пошуку за подібністю. Ви можете завантажити зображення і перевірити, чи є схожі на нього в Інтернеті. Є і інші подібні сервіси: TinEye і Bing Image Match.







